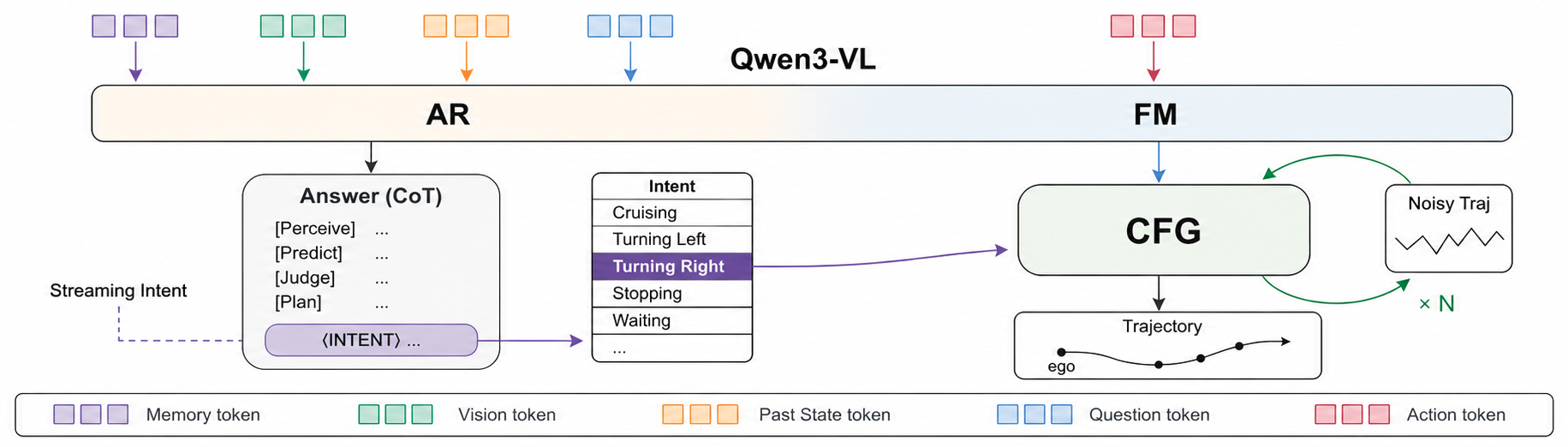
We formalize action emergence — a driving agent's capability to produce physically feasible, semantically appropriate, and safety-compliant actions in arbitrary scenes through on-the-fly reasoning, rather than retrieval or interpolation of learned scene–action mappings — as the missing capability behind long-tail failures of end-to-end driving. Prior autoregressive decoders collapse the multimodal future; diffusion / flow-matching models express multimodality but are not steerable by reasoned intent; existing VLA designs leave language and action structurally disconnected. We propose Streaming Intent (SI) — a single-backbone VLA in which an AR-decoded intent token drives classifier-free guidance on a shared flow-matching action head.
Abstract
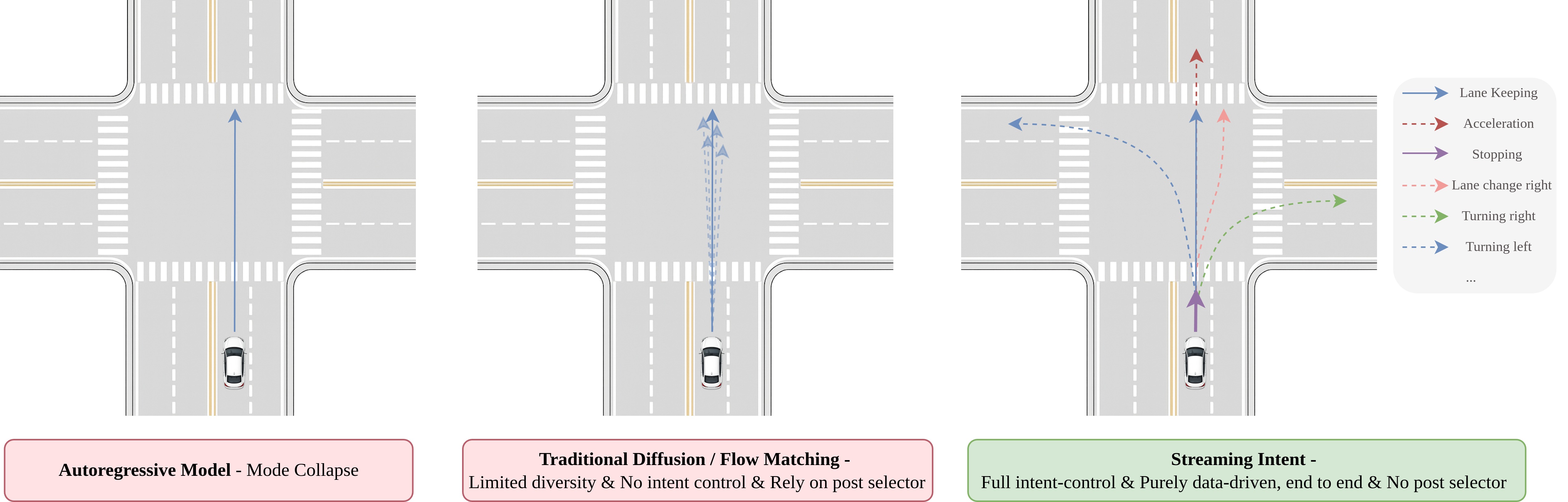
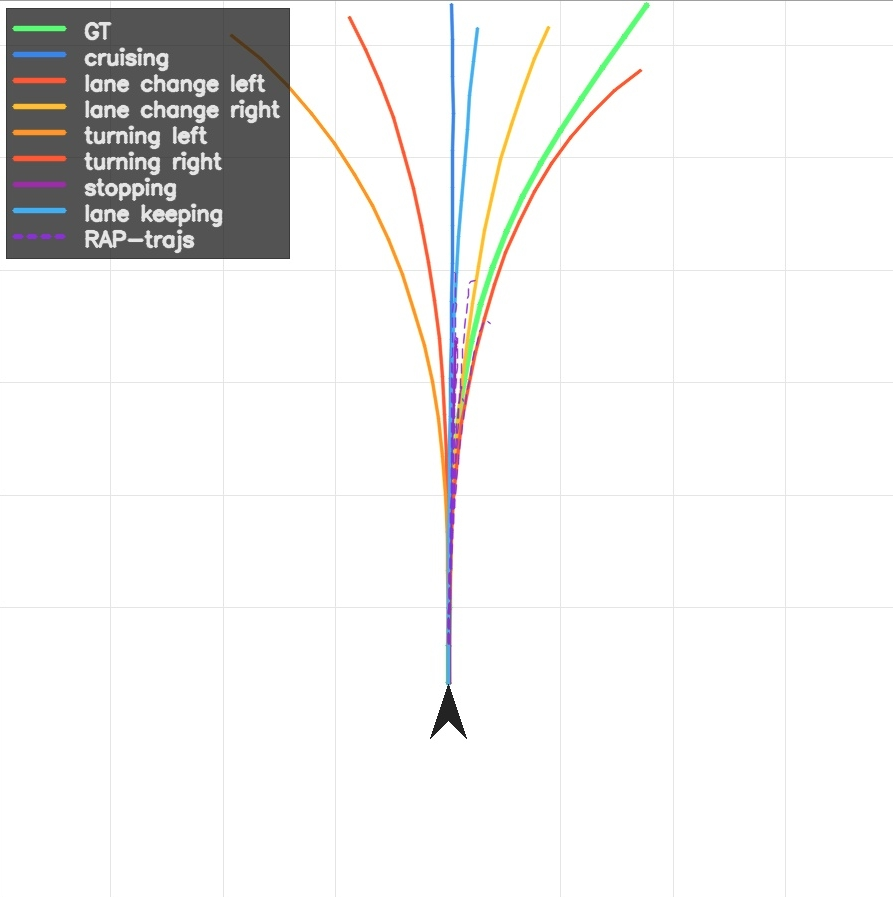
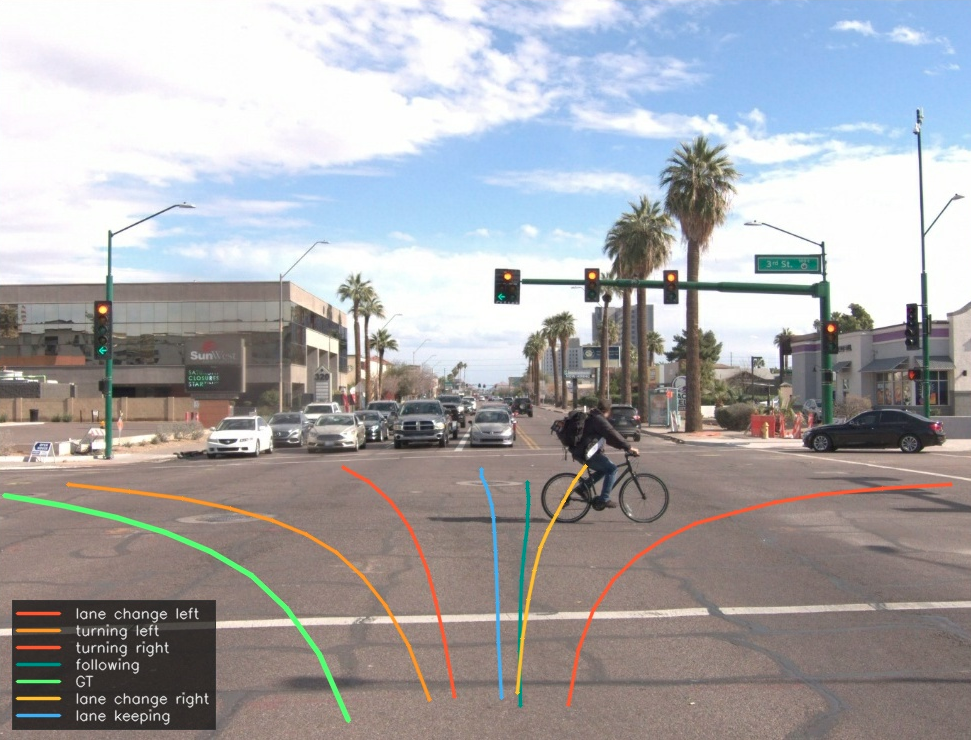
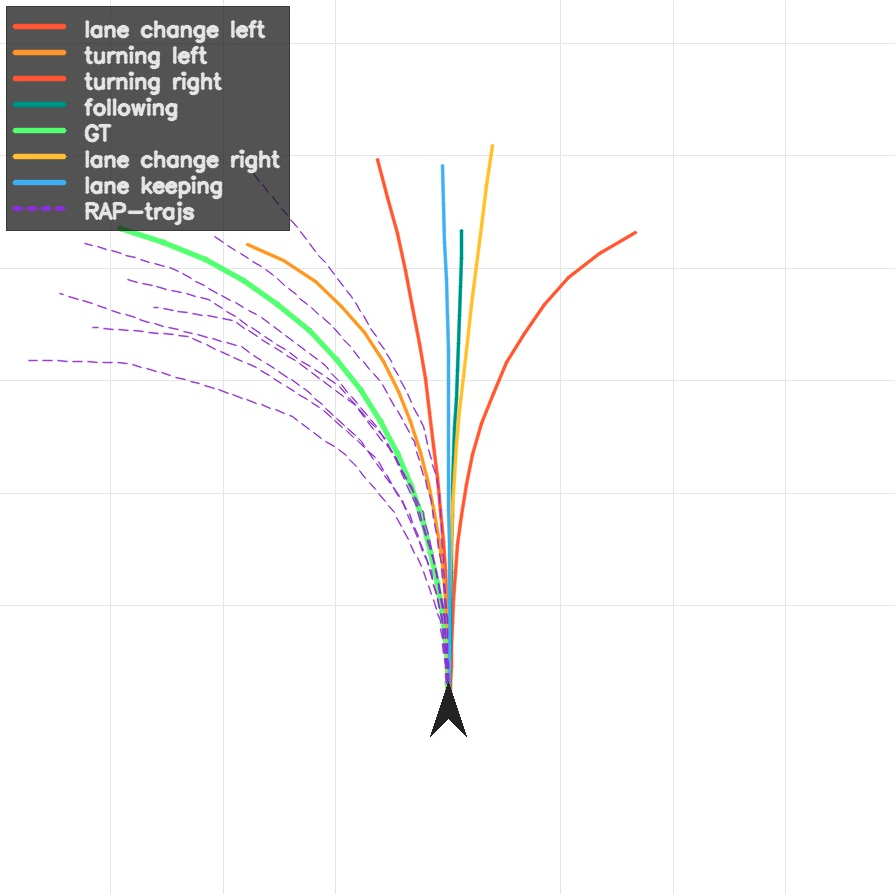
AR models collapse to an averaged future; diffusion / FM models sample a narrow prior-dominated bundle; SI produces intent-faithful trajectories with distinct geometry and speed profiles.